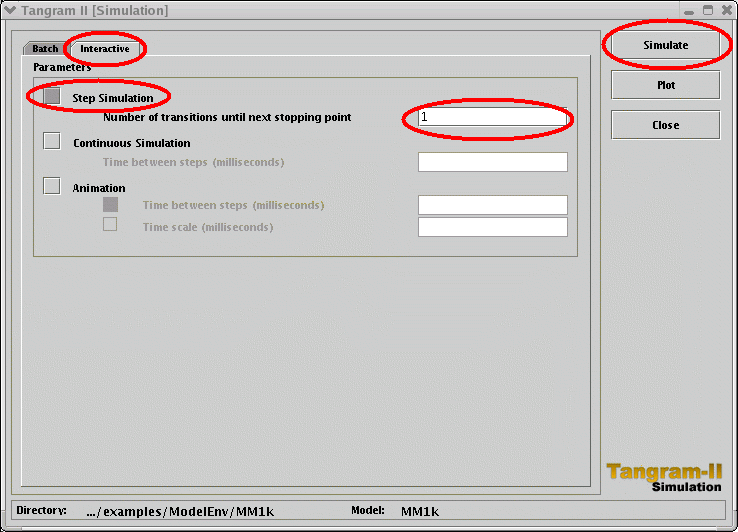
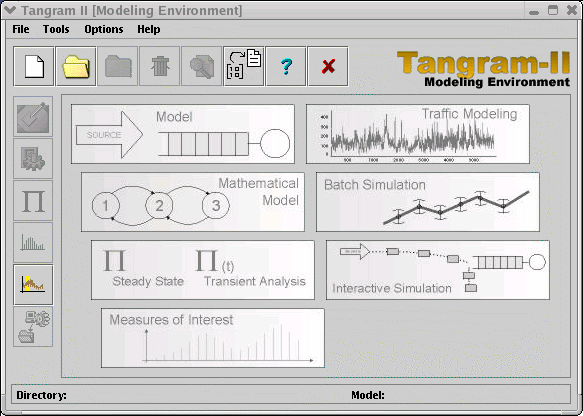
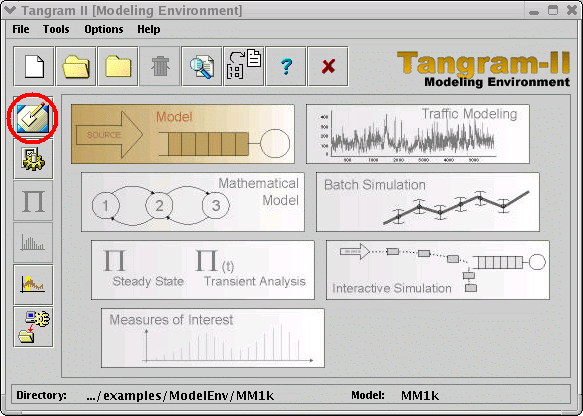
- Click on the "Modeling Environment" button. You will get the "Modeling Environment":
Tangram II is a very flexible tool to construct, solve and simulate
stochastic models. It comes with a manual, and the objective of
this page is to give you a first contact with the tool before (or in
parallel as) you read the manual. Always remember: READ THE MANUAL! :-)
First of all, you need to check the requirements listed above. Then, download the file tangram2-3.0.tar.gz, and run:
tar xvfz tangram2-3.0.tar.gz
cd tangram2-3.0
./configure
make
make install
In this section we will assume that Tangram-II is installed in /usr/local/Tangram2.
 |
Pay attention! Always remember to save the text file which your are editing with your preferred text editor after you make the desired modifications, before proceding to the next step! |
| |
You may change the preferred text editor including one of the following lines to your ~/.Xdefaults file: Then, run One more note: if you want syntax highlight with NEdit, you may copy this file to your home directory, saving it as ~/.nedit. Also, if you experience problems when trying to instantiate an object, you may try to get the following version of Xdefaults, edit the paths to the files referenced properly, and copy it to your home directory (save it as ~/.Xdefaults). Then, type |

|
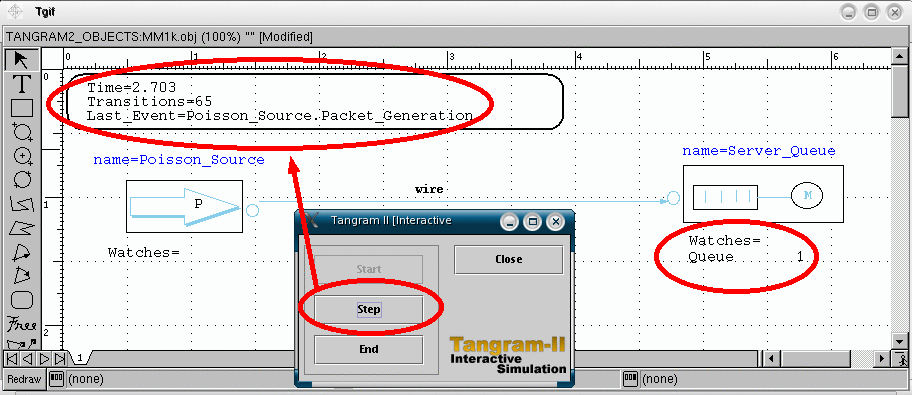
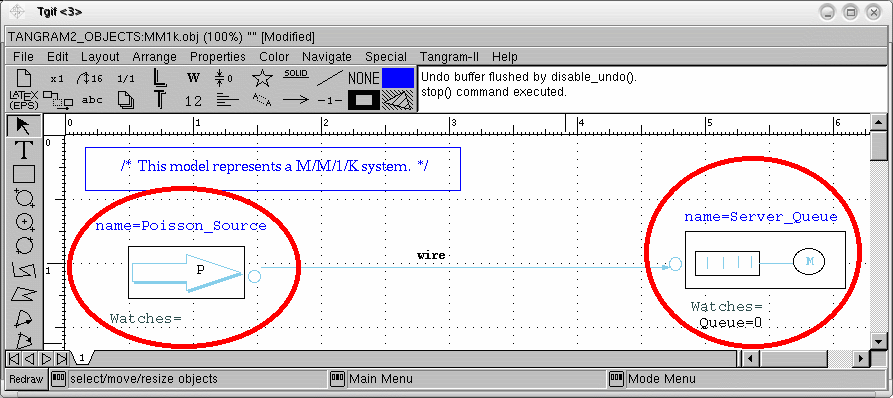
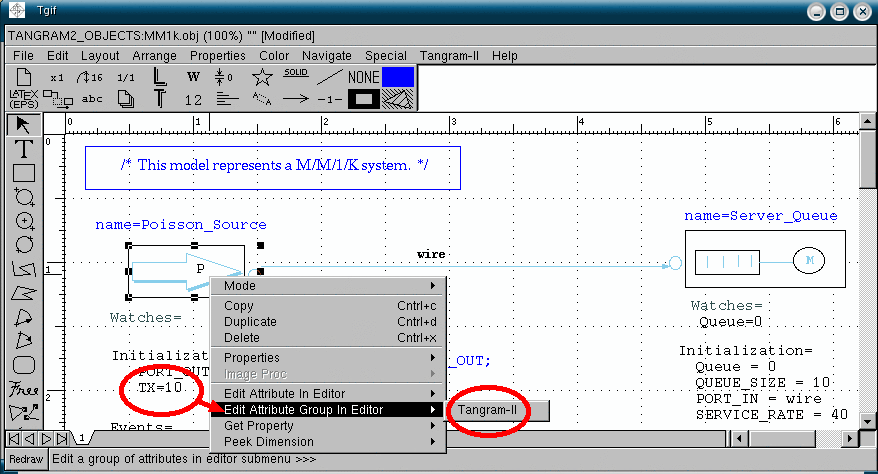
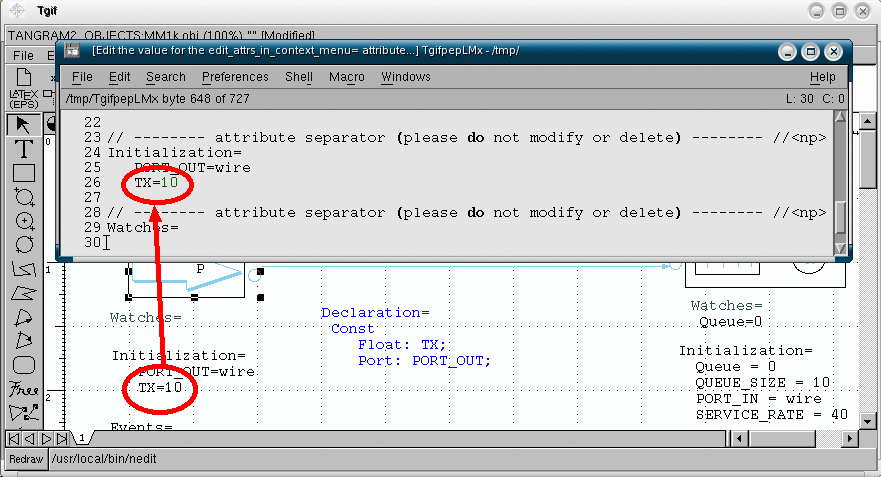
Deprecated: In order to make changes in the model you may also right click on the object which you want to alter, and select "Edit attribute in editor". Then, use your preferred text editor (the default is vi), to modify your model attribute. To modify the Poisson source rate from 10 to 15, in the "Intialization" attribute, see the figure below. |
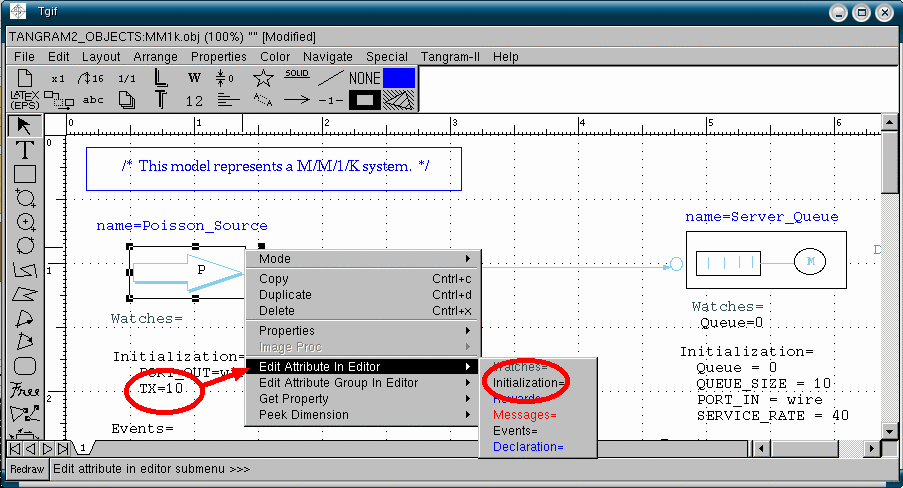
| |
Pay attention! Always remember to save the TGIF file after you make the desired modifications, before proceding to the next step! |
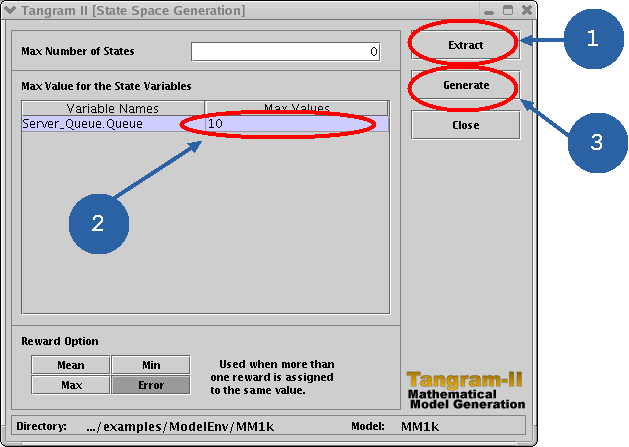
Click first on the "Extract" button. Then fill the field that
corresponds to the maximum value of the state variable
"Server_Queue.Queue" with the value "10" (type 10 and <enter>) and
finally click on "Generate". Note that you may let "Max Number of
States" equal to 0 (zero), as default.
| |
Pay attention! Always remember to click on the "Extract" button when you make any change in the tgif model. The changes will just take effect if you click on the "Extract" button. Also don't forget to press <enter> after filling in the "maximum values" field. Just after that click on "Generate". |
| |
If, when you type the digits (numbers) in the text box, nothing appears on the screen, do the following. First, verify if you are with the focus on the box. Then, disable "NumLock". |
 |
Letting "Max Number of States" equal to zero means that there is no a priori bound on the number of states in the model. |
| |
The state variable "Server_Queue.Queue" is automatically extracted from the model description. In our particular model, we just have one state variable - the size of the queue, which is part of the server object. Note that the state variable name is composed by two parts: before the dot we have the name of the object which defines the state variable, and after the dot the name of the state variable as specified in the "Declaration" section of the object description. |
At this moment, if you take a look at the terminal where you opened the
tangram2, you will see something like this:
| make -f
/usr/local/Tangram2/lib/Makefile.mark_find
TANGRAM2_HOME=/usr/local/Tangram2 BASE=MM1k g++ -O2 -w -g -I. -I/home/daniel/include -I/usr/local/Tangram2/include -c MM1k.user_code.c ...Finished ./mark_find -G -m 0 -f MM1k -d 0 -w 4 ...Finished Total number of states: 11 Total Execution Real Time: 7.045 miliseconds ...Finished ...Finished ...Finished |
Note that our model has 11 states (one corresponding to the empty
system, and the other ten corresponding to the system with one, two,
..., ten clients in the server queue). If, during the "generation"
(compilation) of the model, some error occurred (for instance, a syntax
error), the error would be reported in this terminal, so that you were
able to correct it. You would need to go to step 9 again.
As soon as the model was correctly compiled, you may now click on
"Close".
Note: By "generated" we mean that a Markov chain was generated. The transition rate matrix Q was generated. And we may always obtain the matrix P using the so called method of uniformization! If you want to see the matrix Q, take a look at the file MM1k.generator_mtx.
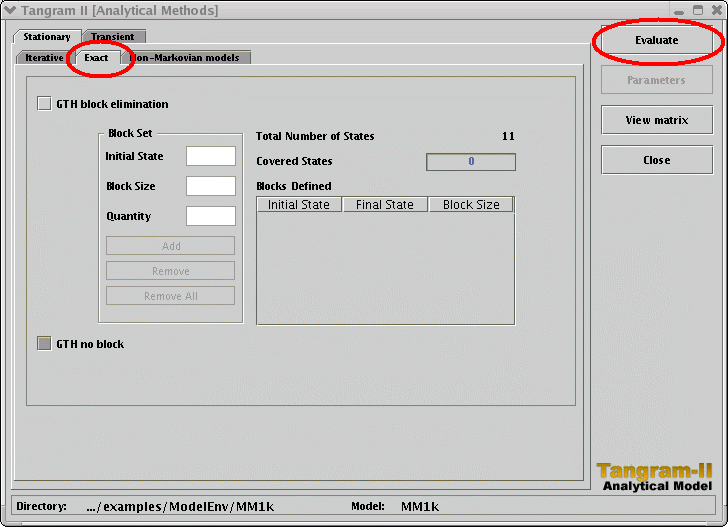
| |
Note that the state variable "Server_Queue.Queue" was declared in the model (take a look at the declaration section of the Server_Queue object). This state variable stores the number of packets in the server queue. |
| |
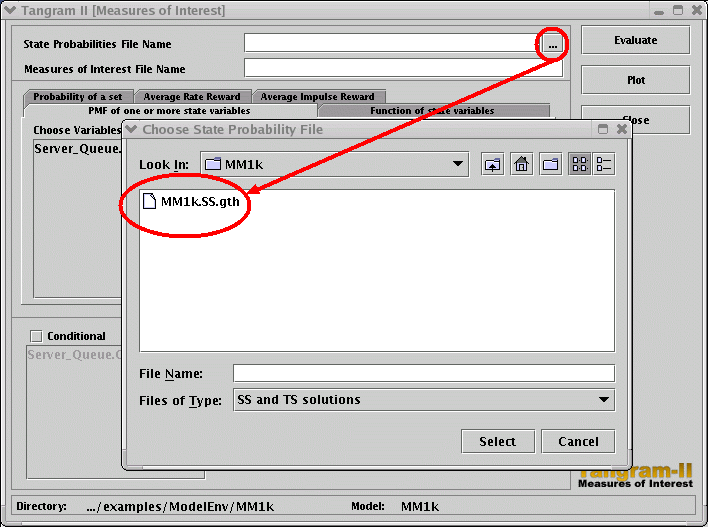
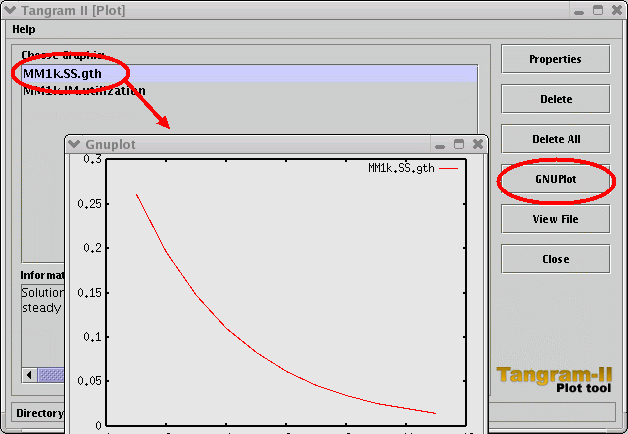
You may take a look at the file MM1k.SS.gth, using your preferred text editor, in order to see the steady state probabilities of the states of your model. In the first column of the file, you have the state number, and in the second one, its steady state probability. |
| |
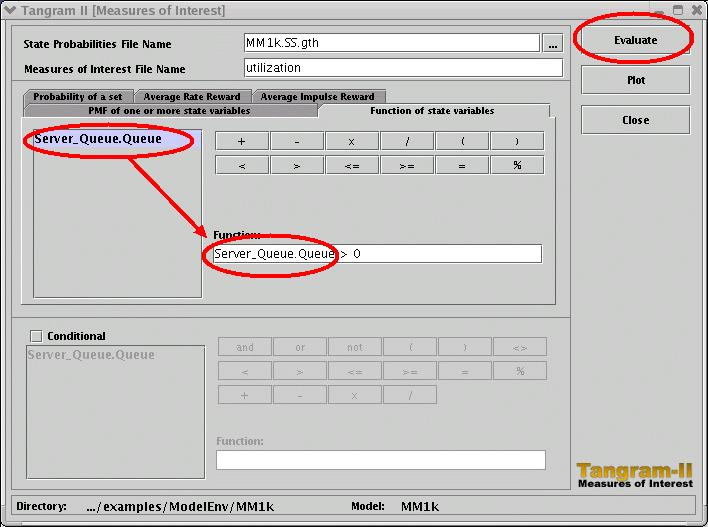
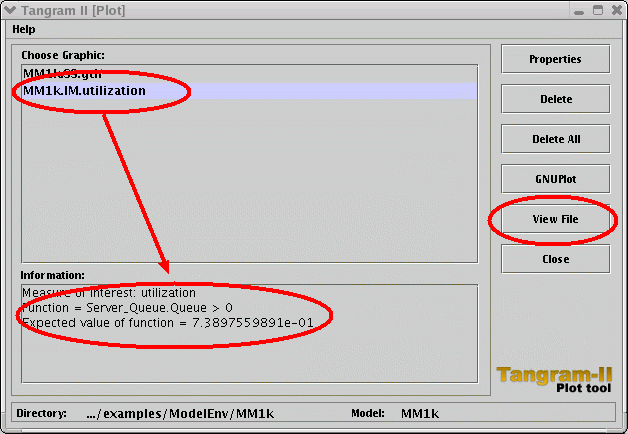
You may evaluate any function of the state variables, involving the operators shown on the screen (+, -, / and so on). For instance, if you would like to evaluate the probability of having the server queue with an odd number of packets, you should use the formula ( Server_Queue.Queue % 2 ) = 1. |
| |
In our particular model, we just have one state variable. If we had more than one state variable, we would need to specify if we want joint distributions or marginal distributions. In order to obtain joint or marginal PMFs, select the tab "PMF of one ore more state variables" in the screen shown in step 17. Then, select one state variable in the left box, and click on the "Add" button. You may repeat this operation if you want joint distributions. Then, click on "Evaluate". |
|
---------------------------------------------------------------
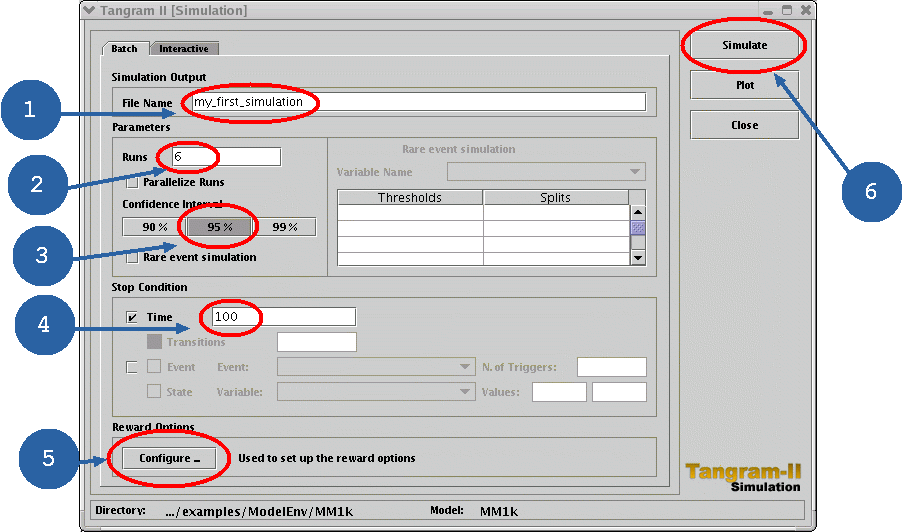
R E W A R D S R E S U L T S --------------------------------------------------------------- Simulation time : 100.000000 Number of runs : 6 Total simulation time : 600.000000 Confidence interval : 95% Simulation execution real time : 2751.332 milliseconds ----------------- Rate Rewards Results ----------------- Measure: Server_Queue.utilization - CR(t) : - mean = 7.3226132520e+01 - var = 3.9265764744e+00 - interval = ± 1.58557751e+00 [7.16405550e+01 , 7.48117100e+01] - ACR(t): - mean = 7.3226132520e-01 - var = 3.9265764744e-04 - interval = ± 1.58557751e-02 [7.16405550e-01 , 7.48117100e-01] |